

Authored by Kylie Zhang, Nimra Nadeem, Lucia Zheng, Dominik Stammbach, Peter Henderson
In a recent TED Talk, Supreme Court attorney Neal Katyal describes how he prepared for his Supreme Court oral arguments in Learning Resources v. Trump, the 2025 tariffs case. Katyal says that he was guided in his journey by four mentors: sports coach Bob, improv coach Liz, “relentless” legal coach Harvey, and meditation coach Ben. Then comes the plot twist: Harvey is actually AI. “I trained it on every question asked by a Supreme Court justice in the last 25 years and everything they’ve written… And in that, patterns emerged. It predicted the contours of the very argument I would face,” Katyal proclaims. Startling and futuristic, Katyal’s speech positions AI as a revolutionary force for oral argument preparation. But does AI as an oral argument simulator live up to the hype?
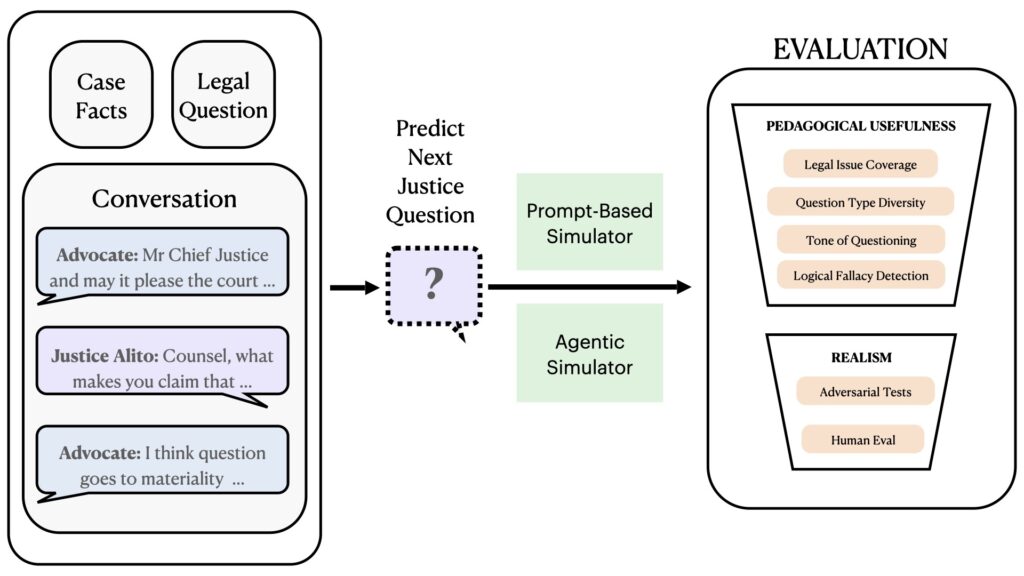
In our recent paper, we present the first comprehensive framework for evaluating AI as a practice partner for oral argument preparation. Given the facts of the case, the legal question, and the oral argument so far, the AI-simulator is tasked with predicting what a specific justice would say next. We construct our task samples using U.S. Supreme Court oral argument transcripts and test both prompt-based and agentic simulators built on top of open and closed source frontier models.
Our evaluation framework combines 20 different metrics to assess the realism and pedagogical usefulness of these AI-generated justice questions. These metrics include whether the simulated questions cover key legal issues, the diversity of question types, the robustness of the simulators against adversarial advocate behavior, and human evaluation of realism.
In line with Katyal’s praises, we found that the best AI simulators actually perform surprisingly well. Human evaluators, including law students, found simulated questions to be very realistic, and often they rated them equally as compelling to actual justice responses. Most models were strong at detecting logical fallacies (over 80% detection rate for seven out of ten tested categories) and were able to broadly address more than 60% of the legal issues raised by actual SCOTUS justices during oral arguments. The latter finding lends credence to claims made by Katyal’s slides, where he compared Harvey’s outputs to what an actual justice said in his case.
But we also found very significant shortcomings. For one, AI simulators were extremely sycophantic and, as a result, performed very poorly on our adversarial tests.
When attorneys deliberately broke courtroom decorum, even the best simulators pushed back less than 40% of the time. When presented with political rage-bait provocations or arguments that switched sides mid-stream, detection rates dropped below 10%.
In other words, most models fail to call out an advocate for abandoning their argument for their opponent’s in the middle of questioning!
Such pushback requires models to disagree with the user, which post-training on human preferences tends to discourage. Real justices readily, and sometimes aggressively, challenge inconsistencies in advocates’ claims. So, an advocate only using an AI legal coach may not be well prepared for that pressure, and may instead erroneously assume that certain problematic behavior is acceptable. Such sycophantic tendencies also imply broader challenges about AI use in pedagogical settings, where it is important to give critical feedback and avoid reinforcing errors.
We also found that AI-generated questions were much less diverse than the types of questions asked by real-world justices. For example, AI simulators almost never ask hypothetical questions. Using hypotheticals to probe an advocate’s argument is common among justices, most notably former SCOTUS Justice Stephen Breyer. Generating good hypotheticals requires understanding the decision boundary the advocate is proposing and constructing fact patterns that test counterfactual worlds. But current models struggle with this kind of analytical creativity.
Also, despite their ability to broadly cover key legal issues (as noted above), when we assessed whether the simulated questions covered the fine-grained details of legal issues raised by real-world justices, we found that even the best model was only able to cover at most 41% of the issues. This finding is in line with Josh Blackman’s critique that many Harvey outputs are only topically related to actual questions asked and fail to capture their full scope and breadth.

We started this line of research because we envision a world with equitable, open, and accessible tools to help improve the status quo in oral argument preparation. While wealthy firms can afford to hire former judges for moot courts, under-resourced attorneys don’t have such luxuries. And because so much of appellate preparation turns on strategizing about how to frame a case in response to these types of questions and get at the heart of lawyering, effective AI sparring partners would meaningfully expand how advocates can prepare effectively for oral arguments.
Our results suggest that while AI for oral argument practice shows significant promise, more research is needed to address substantial limitations like sycophantic behavior. Like Katyal, we agree that Harvey and other legal AI tools are “not some god” but can make for valuable thought partners. But to make good use of this potential, we need a nuanced and thoughtful approach to both training, evaluation, and marketing. Publicizations of shortcomings, in particular, can allow users to adjust their AI usage to avoid known system limitations, which is especially important in high-stakes settings. We hope that researchers and model developers continue to invest in such use cases in order to turn current systems into reliable thought partners that offer constructive critique and help develop – rather than replace – human reasoning.
(For more details on the paper, we also wrote up an interactive webpage, which you can find on the POLARIS Lab’s blog.)
Kylie Zhang is an M.S.E. student in the Department of Computer Science advised by Peter Henderson. She’s interested in the legal implications of emerging technologies and how they impact systems of social cohesion.
Nimra Nadeem is an MSE computer science student at Princeton, advised by Peter Henderson, working at the POLARIS Lab, and affiliated with the Center for Information Technology Policy. Nadeem’s research explores how large language models interpret and apply natural language rules, drawing on insights from law and philosophy. She is especially interested in interpretive ambiguity (both in AI alignment and in law), legal reasoning in LLMs, and developing normative sociopolitical theories of justice in the age of AI.
Dominik Stammbach is a postdoctoral researcher who explores applications and the new development of Natural Language Processing (NLP) methods. He is especially interested in NLP for enhancing access to justice, making law accessible, developing methods to detect misinformation and corporate greenwashing. Stammbach’s work combines a focus on high-quality data and recent trends in NLP.
Lucia Zheng is a JD/CS PhD student at Stanford whose research focuses on the intersection of machine learning, NLP, and law. I’m interested in improving language modeling for reasoning in environments where information is incomplete and shaped by competing interpretations, norms, and institutions, with an eye towards supporting public interest applications.
Peter Henderson is an assistant professor at Princeton University whose research focuses on aligning machine learning, law, and policy for responsible real-world deployments. This includes work on AI safety, methods to improve reasoning in foundation models, interdisciplinary methods in law and AI, as well as core work on legal doctrine and policy, particularly around AI governance. Henderson received his J.D. from Stanford Law School and Ph.D. in computer science from Stanford University.
Leave a Reply