

Authored by : Patty Liu, Dominik Stammbach, Peter Henderson
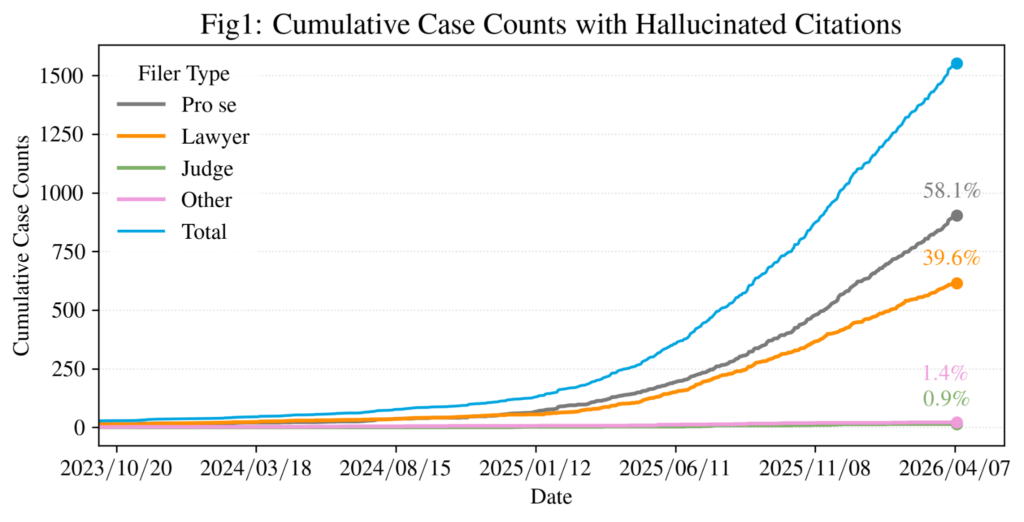
Fabricated case citations generated by AI are appearing in court filings at an accelerating rate.
Combined with other tracking efforts, we have identified over 1,000 filings containing hallucinated citations from self-represented (pro se) litigants and lawyers alike. Fabricating citations, or misrepresenting the content of those citations, is the same as pointing to made-up law to win the case. Courts have called it “an abuse of the adversary system” that risks the integrity of the judicial process. Mata v. Avianca, Inc., 678 F.Supp.3d 443, 461 (S.D.N.Y. 2023); see also Park v. Kim 91 F.4th 610, 615 (2d Cir. 2024) (quoting Mata); Noland v. Land of the Free, 114 Cal. App. 5th 426, 445 (2025) (quoting Mata). Another described the resulting verification burden as an “enormous waste of judicial resources,” and noted the necessity of increasing penalties as “lesser sanctions have been insufficient to deter the conduct.” Mid Central Operating Engineers Health and Welfare Fund v. HoosierVac LLC, 2025 WL 574234, at *3 (S.D.Ind. Feb. 21, 2025). In all, courts have to spend large judicial resources tracking down hallucinations and verifying citations—and it disadvantages pro se litigants, frustrates judges, and erodes trust in the legal system.
In new research, we examined whether AI can also reduce burdens on courts by automatically verifying citations, introducing LePhantomCite, a new benchmark for automatic legal citation verification.
We find that:
- Free- or low-cost-tier model hallucination rates are likely not improving in legal contexts;
- Models are improving at agentic cite-checking, but still have room for improvement on our LePhantomCite benchmark, especially given the high stakes and low error tolerance of hallucinated citations;
- Current lack of access means that there is a limit to what agents (and pro se clients) can verify—courts should consider providing free access to all reporters and canonical versions of legal opinions to give pro se clients the necessary means to verify LLM-generated output, and to improve automatic cite-checking.
We hope this work sets off new efforts to reduce court verification burdens, and improves responsible AI model development.
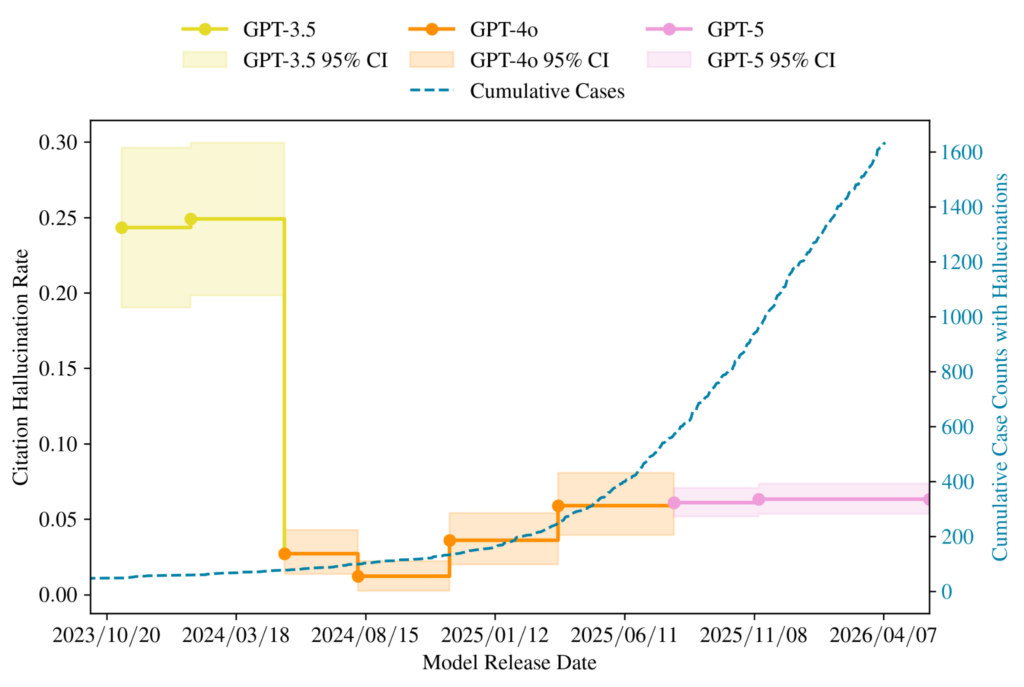
New AI models still hallucinate, and often more than before.
In a controlled experiment, we evaluated eight generations of free-tier ChatGPT models (Figure 2). We queried these models on the same ~100 legal drafting prompts, producing over 8,000 citations which we verified against CourtListener and Westlaw. Early GPT-4o models improved substantially over the GPT-3.5 models, but the trend didn’t persist: GPT-5.1 hallucinates at 6.57%, a statistically significant regression (using bootstrapping, p = 0.001).
Raw hallucination rates alone also understate the growing verification burden. Newer models generate more citations per document, drawn from a broader, less canonical set of cases that can take longer to verify. Such additional work stretches a judicial system already at its limit: The Federal Judicial Caseload Statistics reports that 633,000 civil cases were pending in 2025.
Not all hallucinations are the same: a legal citation hallucination taxonomy
To understand legal citation hallucinations better, we developed a taxonomy of hallucination types observed and discussed in real court filings. Understanding these categories matters because they require different verification methods and have different policy implications.
- Non-existent citations: the cited case doesn’t appear anywhere.
- Case name mismatches: the reporter citation points to a real case, but a different one than the named case.
- Incorrect pincites: the citation refers to the correct case but the cited page number doesn’t support the quoted language or proposition.
- Verbatim misquotes: the quoted language does not appear exactly in the cited case.
- Content misrepresentation: a real, correctly cited case being used to support a legal proposition it does not stand for.
These categories help identify different challenges in legal hallucination detection: non-existent citations and name mismatches can be identified with database lookups, whereas the other three require access to the opinions.
Can AI verify legal citations?
To evaluate whether automated verification is a viable path forward, we introduce LePhantomCite (Legal Phantom Citation), a benchmark dataset of 1,300 legal brief excerpts with injected hallucinations drawn from these five categories. The dataset is constructed from real federal appellate briefs filed between 2012 and 2021 — pre-dating widespread AI adoption, to ensure clean source material — augmented with 300 entries from an existing LLM-generated holdings dataset from Dahl et al. (2024) that we manually verified against Westlaw.
We evaluated five models on this dataset both in standard and agentic settings. In the agentic setting, models can iteratively search legal databases and the open web before reaching a verdict.
The results suggest that automatic cite-checking might be an increasingly viable option for reducing the burden on courts. GPT-5 in the agentic framework achieves 82.8% recall, nearly 20 percentage points better than its non-agentic baseline. The agent reliably catches non-existent citations (100% recall) and case name mismatches (97.1%), and performs well on verbatim misquotes (82.6%) and content misrepresentation (84.0%). The agent even surfaced more than ten citation typos in pre-LLM appellate briefs that human authors had missed! For instance, one brief in Abbey v. United States cited “Vela v. City of Houston, 216 F.3d 659 (5th Cir. 2001)” where the correct reporter citation is “276 F.3d 659”, and another in Loveridge v Hall quoted “jurisdiction over all civil proceedings […]” where the correct phrasing is “jurisdiction of all civil proceedings […]”.
Conversely, though, GPT-5 catches only 18.2% of incorrect pincites. This is not due to model capability but a lack of access to information. Official pagination often isn’t included in free public databases.
What can be done
We argue that we need other solutions to better support pro se litigants and alleviate verification burden:
1. Improve access to legal information
Verification is difficult for everyone, but especially for those without access to commercial legal databases. This is not only a problem for pro se filers but also directly limits what free automated verification tools can achieve. Many opinions are only available behind paywalls on Westlaw or Lexis—or sometimes not even there. Expanding free public access to legal opinions in the United States and official canonical formats would improve both human and automated verification for under-resourced filers. Though efforts like CourtListener and the Free PACER movement have made some progress, they still do not have complete coverage (as our work shows).
Outside of the US, efforts to make the law more accessible have borne some fruit. Canada’s CanLII, a free nonprofit database covering all Canadian jurisdictions, provides free, centralized access to most court opinions. Canadian courts can reasonably expect even unrepresented parties to verify whether a cited case exists, because the database makes that possible. However, even CanLII can improve. At the time of writing, CanLII does not allow automated agentic access, which makes it impossible for open-source automatic cite-checking efforts to leverage the database.
2. Courts could explore technical screening.
Pro se filings today are sometimes screened and processed by law clerks. And recently, a collaboration between Stanford and LA County introduced new AI tools to screen default judgments for defects. Introducing a similar automated screening tool could help reduce court burdens by flagging potential issues at, or before, filing time. Law clerks, rather than being replaced by AI, could spend more time helping pro se litigants navigate the legal system with the improved filings, rather than chasing hallucinated citations.
3. Courts should update pro se guidance.
Courts already provide instructions to pro se filers, but they do not contain any mentions of AI usage, the phenomenon of hallucinations, or potential sanctions for hallucinated citations (See New Jersey Procedural Guide for Pro Se Litigants from December 2024 as an example guide). They should: 1) explain hallucination risks, 2) clarify potential sanctions, and 3) most importantly, offer instructions and easily-accessible tools for verifying citations.
4. Model providers should continue to improve hallucination rates, especially in legal outputs in free-tier models.
Hallucinated citations were exceedingly rare before generative AI. Model and system providers—from ChatGPT to LexisNexis and Westlaw—should continue to reduce hallucination rates that have, as our work shows, stagnated in free-tier systems. In particular, these model providers should consider implementing additional guardrails like:
- Built-in verification of citations and arguments for free-tier models
- Improving model abilities to automatically cite-check—such as by improving LePhantomCite benchmark scores.
- Having models abstain if they are not capable enough for legal uses, or automatically switching to more advanced models for high-stakes legal queries.
- Setting legal hallucination rates as a key top-priority area of monitoring and improvement, even for the most accessible free-tier models.
Hallucinated legal citations are a growing systemic problem. Courts, litigants, and the public are bearing the costs. But these burdens can be reduced by updating policies around accessibility of the law, developing better verification tools, ensuring responsible model design, and improving awareness. To address these challenges, our work introduces new benchmarks, tools, and evaluations to continue to monitor and improve hallucination rates and automatic cite-checking.
Leave a Reply