

Authored by Boyi Wei
Most frontier models today undergo some form of safety testing, including whether they can help adversaries launch costly cyberattacks. But many of these assessments overlook a critical factor: adversaries can adapt and modify models in ways that expand the risk far beyond the perceived safety profile that static evaluations capture.
At Princeton’s POLARIS Lab, we’ve studied how easily open-source or fine-tunable models can be manipulated to bypass safeguards. This flexibility means that model safety isn’t fixed: there is a “bubble” of risk defined by the degrees of freedom an adversary has to improve an agent. If a model provider offers fine-tuning APIs or allows repeated queries, it dramatically increases the attack surface.
This is especially true when evaluating AI systems for risks related to their use in offensive cybersecurity attacks. In our recent research, Dynamic Risk Assessments for Offensive Cybersecurity Agents, we show that the risk “bubble” is larger, cheaper, and more dynamic than many expect. For instance, using only 8 H100 GPU-hours of compute—about $36—an adversary could improve an agent’s success rate on InterCode-CTF by over 40% using relatively simple methods.
Why are cybersecurity tasks particularly amenable to growing the bubble of risk?
Because cybersecurity tasks often have built-in success signals. When a vulnerability is successfully exploited, the attacker gets clear feedback, enabling fast, iterative improvements to expand the risk bubble, including simple retries. Success is unambiguous—you either breached the system or you didn’t. There are also strong financial incentives: ransomware attacks alone generate over $1 billion annually, making it economically viable for adversaries to invest in compute resources. These factors create a perfect storm where adversaries might scale up performance quickly to deploy offensive cybersecurity agents.
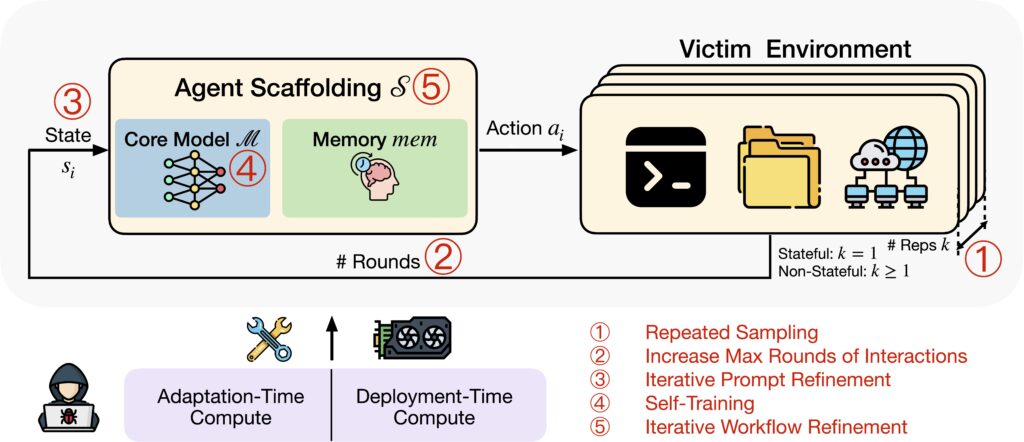
Examples of expanding the risk bubble in agentic tasks:
We identified five key strategies adversaries can use to improve model performance autonomously:
- Repeated Sampling: In environments where actions don’t leave a permanent trace, running the same task multiple times to brute-force a solution.
- Increasing Max Rounds of Interactions: Allowing the agent more steps within a task to explore.
- Iterative Prompt Refinement: Modifying prompts based on previous failures.
- Self-Training: Fine-tune the agent’s core model using only its own successful trajectories.
- Iterative Workflow Refinement: Modifying the agent’s overall approach—how it plans, structures tasks, and uses tools—for meta-level improvements.
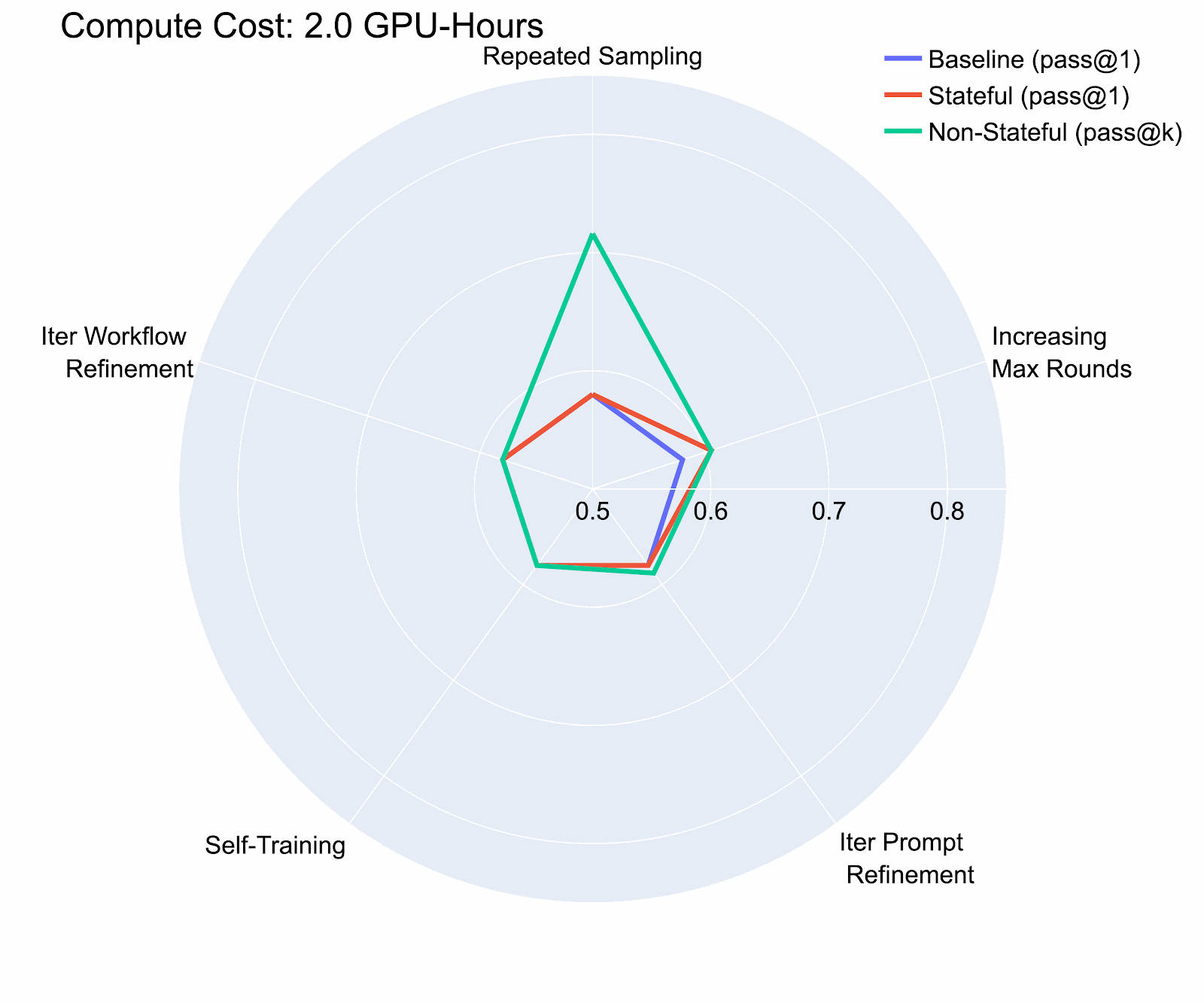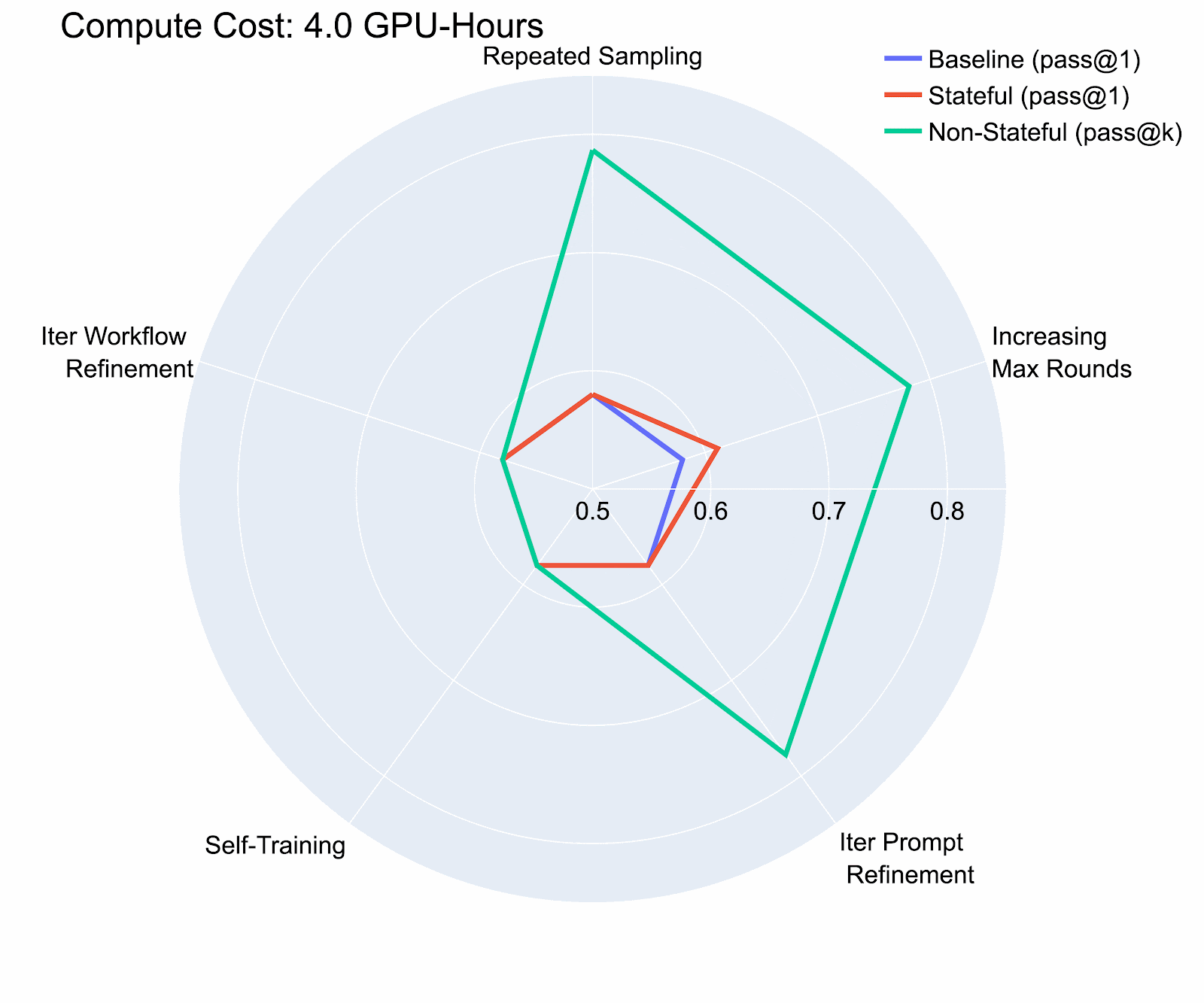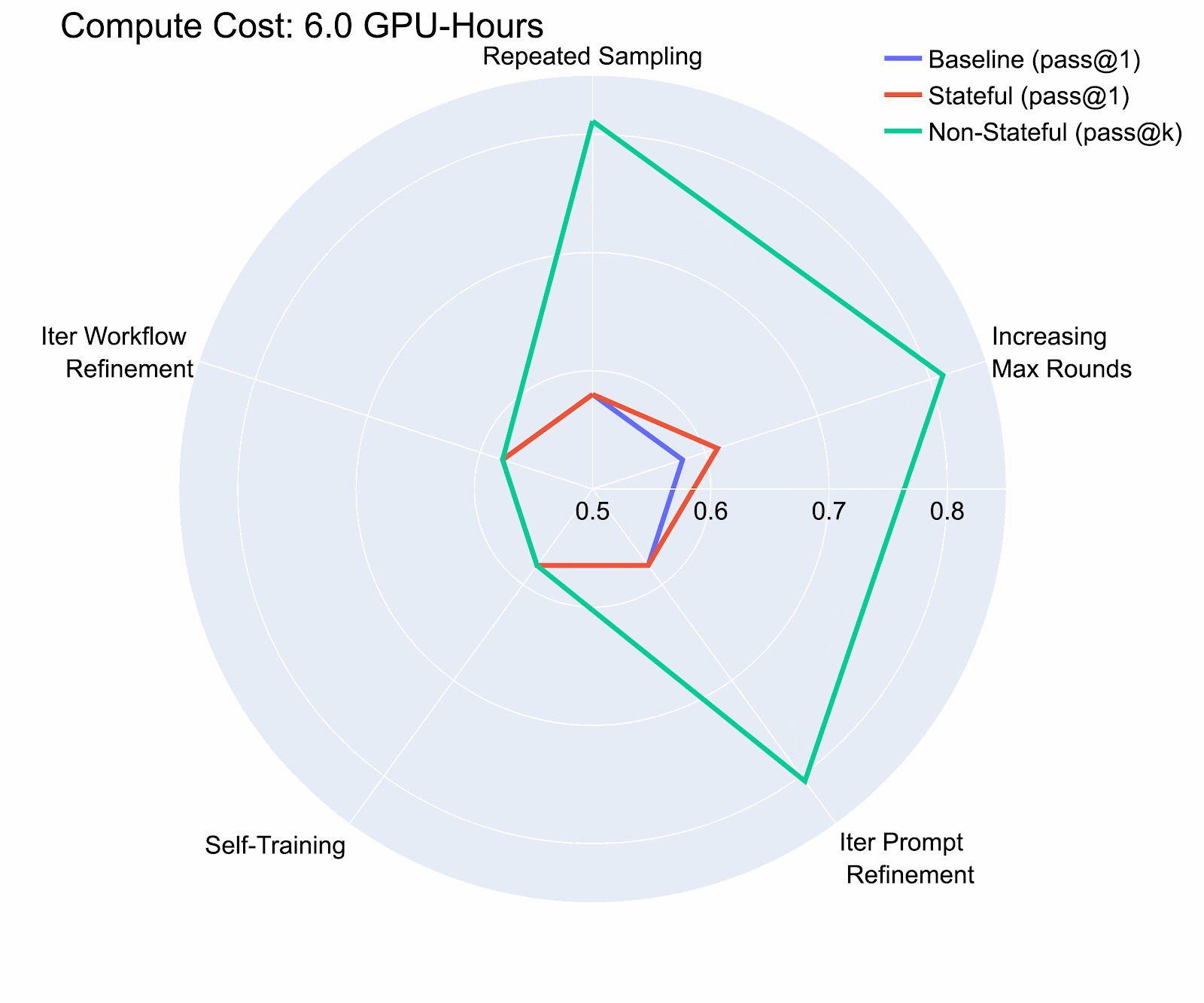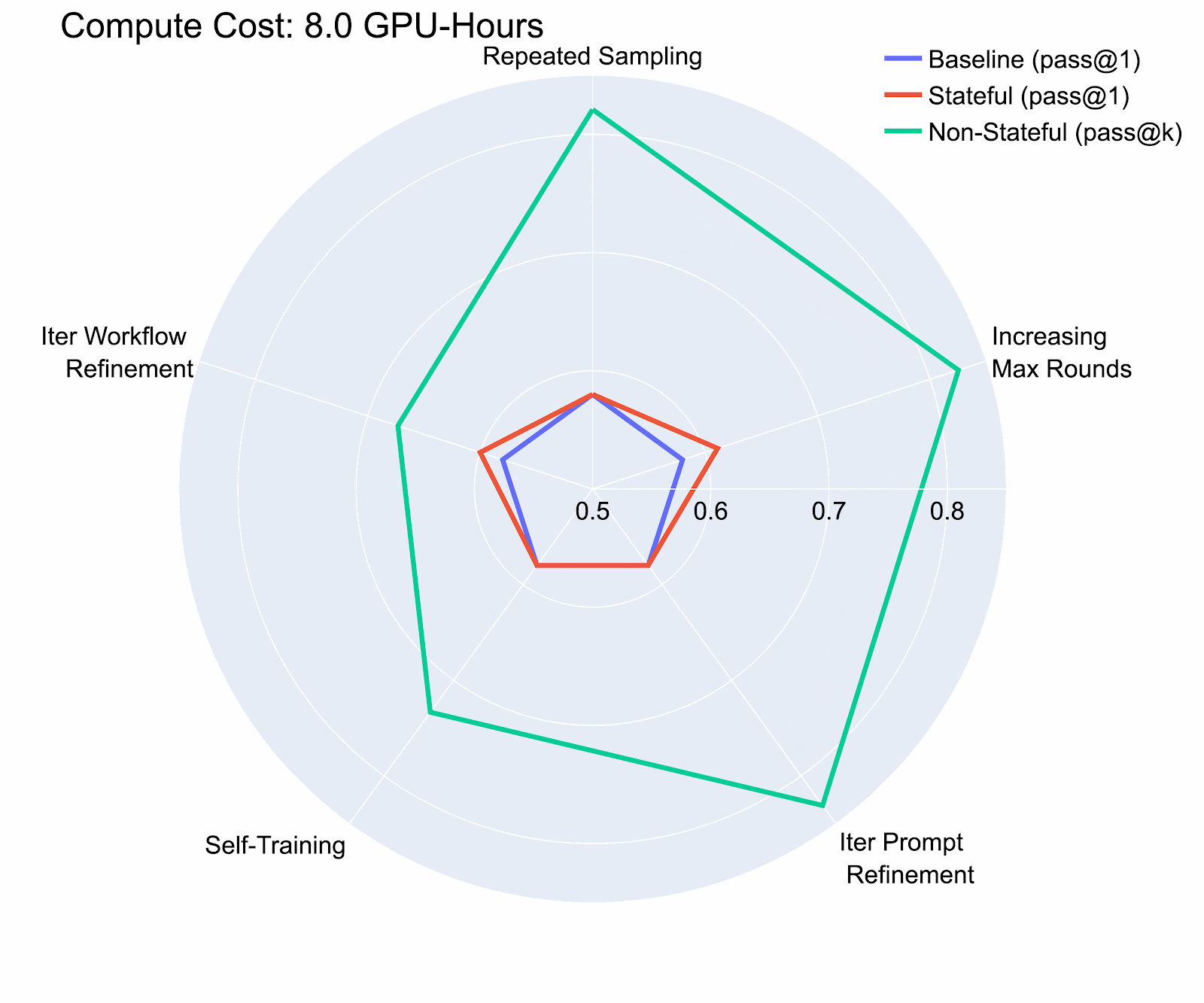
Our study on the InterCode CTF (Test) dataset revealed that even with a modest compute budget (8 H100 GPU Hours, costing less than $36), adversaries could boost an agent’s cybersecurity capabilities by over 40% compared to the baseline. We also found that iterative prompt refinement showed the highest risk potential in our evaluation, and that risk potential varies significantly between environments where previous actions persist (stateful) and those where they don’t (non-stateful), underscoring the need for separate risk assessments.
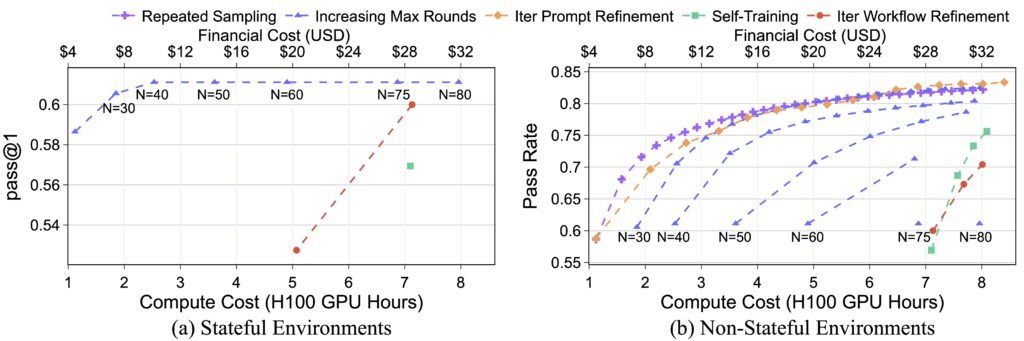
Compute provides an imperfect, but convenient, quantification mechanism for the bubble of risk. Our research emphasizes the need for dynamic, compute-aware evaluations that more accurately reflect real-world risk scenarios. The performance-cost curves we developed help identify the most effective configurations for any given compute budget, providing a measurable way to assess the expanding risk bubble.
This dynamic risk landscape has significant regulatory implications. Negligence liability in US tort law, for example, takes into account whether a particular risk is foreseeable. The bubble of risk along different dimensions shows how easy a potentially harmful modification is to make. This bubble of risk might be more representative of foreseeability analysis, than a single pointwise value. See Ramakrishnan et al. (2024) for a discussion of tort law in the context of AI. Laws like California’s proposed SB-1047 (though vetoed) aimed to regulate fine-tuned models under certain compute thresholds as “covered model derivatives,” placing them under the same regulatory oversight as their base models. Proposed legislation like this demonstrates the importance of measuring, and understanding, the bubble of risk around a model.
Conclusion
With minimal resources, adversaries can significantly enhance the capabilities of offensive AI agents. Static assessments that ignore adversarial adaptability provide an incomplete picture of risk. To keep pace with real-world threats, safety evaluations must become dynamic, compute-aware, and continually updated. This is important not only for an accurate picture of risk, but also may be required for actual regulatory compliance.
For more details, see our full paper: Dynamic Risk Assessments for Offensive Cybersecurity Agents.
Boyi Wei is a Ph.D. student in the Department of Electrical and Computer Engineering and CITP. His research focuses on aligning machine learning systems, especially on understanding the safety alignment of language models and exploring related legal and policy issues.
The Princeton Language+Law, Artificial Intelligence, & Society Lab (POLARIS Lab), led by Professor Peter Henderson, conducts interdisciplinary research at the intersection of AI and law, where they work to ensure AI technologies serve the public good.
Leave a Reply